vunderba
2 months ago
Okay results are in for GenAI Showdown with the new gpt-image 1.5 model for the editing portions of the site!
https://genai-showdown.specr.net/image-editing
Conclusions
- OpenAI has always had some of the strongest prompt understanding alongside the weakest image fidelity. This update goes some way towards addressing this weakness.
- It's leagues better at making localized edits without altering the entire image's aesthetic than gpt-image-1, doubling the previous score from 4/12 to 8/12 and the only model that legitimately passed the Giraffe prompt.
- It's one of the most steerable models with a 90% compliance rate
Updates to GenAI Showdown
- Added outtakes sections to each model's detailed report in the Text-to-Image category, showcasing notable failures and unexpected behaviors.
- New models have been added including REVE and Flux.2 Dev (a new locally hostable model).
- Finally got around to implementing a weighted scoring mechanism which considers pass/fail, quality, and compliance for a more holistic model evaluation (click pass/fail icon to toggle between scoring methods).
If you just want to compare gpt-image-1, gpt-image-1.5, and NB Pro at the same time:
https://genai-showdown.specr.net/image-editing?models=o4,nbp...
quietbritishjim
2 months ago
Absolutely fabulous work.
Ludicrously unnecessary nitpick for "Remove all the brown pieces of candy from the glass bowl":
> Gemini 2.5 Flash - 18 attempts - No matter what we tried, Gemini 2.5 Flash always seemed to just generate an entirely new assortment of candies rather than just removing the brown ones.
The way I read the prompt, it demands that the candies should change arrangement. You didn't say "change the brown candies to a different color", you said "remove them". You can infer from the few brown ones that you can see that there are even more underneath - surely if you removed them all (even just by magically disappearing them) then the others would tumble down into a new location? The level of the candies is lower than before you started, which is what you'd expect if you remove some. Maybe it's just coincidence, but maybe this really was its reasoning. (It did unnecessarily remove the red candy from the hand though.)
I don't think any of the "passes" did as well as this, including Gemini 3.0 Pro Image. Qwen-Image-Edit did at least literally remove one of the three visible brown candies, but just recolored the other two.
vunderba
2 months ago
That is a great point! Since we are moving towards better "world models" in terms of these multimodal models, you could reasonably argue that if the directive was to physically remove the candy that in the process of doing so, gravity/physics could affect the positioning of other objects.
You will note that the Minimum Passing Criteria allows for a color change in order to pass the prompt but with the rapid improvements in generative models, I may revise this test to be stricter, only allowing "Removal" to be considered as pass as opposed to a simple color swap.
pierrec
2 months ago
This showdown benchmark was and still is great, but an enormous grain of salt should be added to any model that was released after the showdown benchmark itself.
Maybe everyone has a different dose of skepticism. Personally I'm not even looking at results for models that were released after the benchmark, for all this tells us, they might as well be one-trick ponies that only do well in the benchmark.
It might be too much work, but one possible "correct" approach for this kind of benchmark would to periodically release new benchmarks with new tests (that are broadly in the same categories) and only include models that predate each benchmark.
vunderba
2 months ago
Yeah that’s a classic problem, and it's why good tests are such closely guarded secrets: to keep them from becoming training fodder for the next generation of models. Regarding the "model date" vs "benchmark date" - that's an interesting point... I'll definitely look into it!
I don't have any captcha systems in place, but I wonder if it might be worth putting up at least a few nominal roadblocks (such as Anubis [1]) to at least slow down the scrapers.
A few weeks ago I actually added some new, more challenging tests to the GenAI Text-to-Image section of the site (the “angelic forge” and “overcrowded flat earth”) just to keep pace with the latest SOTA models.
In the next few weeks, I’ll be adding some new benchmarks to the Image Editing section as well~~
echelon
2 months ago
The Blender previz reskin task [1] could be automated! New test cases could be randomly and procedurally generated (without AI).
Generate a novel previz scene programatically in Blender or some 3D engine, then task the image model with rendering it in a style (or to style transfer to a given image, eg. something novel and unseen from Midjourney). Another test would be to replace stand in mannequins with identities of characters in reference images and make sure the poses and set blocking match.
Throw in a 250 object asset pack and some skeletal meshes that can conform to novel poses, and you've got a fairly robust test framework.
Furthermore, anything that succeeds from the previz rendering task can then be fed into another company's model and given a normal editing task, making it doubly useful for two entirely separate benchmarks. That is, successful previz generations can be reused as image edit test cases - and you a priori know the subject matter without needing to label a bunch of images or run a VLM, so you can create a large set of unseen tests.
[1] https://imgur.com/gallery/previz-to-image-gpt-image-1-x8t1ij...
somenameforme
2 months ago
You don't need skepticism, because even if you're acting in 100% good faith and building a new model, what's the first thing you're going to do? You're going to go look up as many benchmarks as you can find and see how it does on them. It gives you some easy feedback relative to your peers. The fact that your own model may end up being put up against these exact tests is just icing.
So I don't think there's even a question of whether or not newer models are going to be maximizing for benchmarks - they 100% are. The skepticism would be in how it's done. If something's not being run locally, then there's an endless array of ways to cheat - like dynamically loading certain LoRAs in response to certain queries, with some LoRAs trained precisely to maximize benchmark performance. Basically taking a page out of the car company playbook in response to emissions testing.
But I think maximizing the general model itself to perform well on benchmarks isn't really unethical or cheating at all. All you're really doing there is 'outsourcing' part of your quality control tests. But it simultaneously greatly devalues any benchmark, because that benchmark is now the goal.
smusamashah
2 months ago
I think training image models to pass these very specific tests correctly will be very difficult for any of these companies. How would they even do that?
8n4vidtmkvmk
2 months ago
Hire a professional Photoshop artist to manually create the "correct" images and then put the before and after photos into the training data. Or however they've been training these models thus far, i don't know.
And if that still doesn't get you there, hash the image inputs to detect if its one of these test photos and then run your special test-passer algo.
smusamashah
2 months ago
I don't think a few images done by any professional will have a measurable impact in training.
hdjrudni
2 months ago
I'm sure there's a way for them to give enough weight if they really cared enough. I don't think they should or would, but they could stuff the training data with thousands of slight variations if they wanted to or manually give them more importance. This might adversely affect everything else, but that's another story.
KeplerBoy
2 months ago
"Remove all the trash from the street and sidewalk. Replace the sleeping person on the ground with a green street bench. Change the parking meter into a planted tree."
What a prompt and image.
__alexs
2 months ago
Looking forward to the first AR glasses to include live editing of the world like this.
nisegami
2 months ago
How long until this shows up in a YC batch?
walrus01
2 months ago
I've already seen images on the MLS uploaded by real estate agents that look like this is the same concept as what they've been doing, generally, to bait people into coming and touring houses.
imdsm
2 months ago
A way it could be...
smusamashah
2 months ago
Z-image was released recently and that's what /r/StableDiffusion all talks about these days. Consider adding that too. It is very good quality for its size (Requires only 6 or 8 gigs of ram).
vunderba
2 months ago
I've actually done a bit of preliminary testing with ZiT. I'm holding off on adding it to the official GenAI site until the base and edit models have been released since the Turbo model is pretty heavily distilled.
echelon
2 months ago
I really love everything you're doing!
Personal request: could you also advocate for "image previz rendering", which I feel is an extremely compelling use case for these companies to develop. Basically any 2d/3d compositor that allows you to visually block out a scene, then rely on the model to precisely position the set, set pieces, and character poses.
If we got this task onto benchmarks, the companies would absolutely start training their models to perform well at it.
Here are some examples:
gpt-image-1 absolutely excels at this, though you don't have much control over the style and aesthetic:
https://imgur.com/gallery/previz-to-image-gpt-image-1-x8t1ij...
Nano Banana (Pro) fails at this task:
https://imgur.com/a/previz-to-image-nano-banana-pro-Q2B8psd
Flux Kontext, Qwen, etc. have mixed results.
I'm going to re-run these under gpt-image-1.5 and report back.
Edit:
gpt-image-1.5 :
https://imgur.com/a/previz-to-image-gpt-image-1-5-3fq042U
And just as I finish this, Imgur deletes my original gpt-image-1 post.
Old link (broken): https://imgur.com/a/previz-to-image-gpt-image-1-Jq5M2Mh
Hopefully imgur doesn't break these. I'll have to start blogging and keep these somewhere I control.
vunderba
2 months ago
Thanks! A highly configurable Previz2Image model would be a fantastic addition. I was literally just thinking about this the other day (but more in the context of ControlNets and posable kinematic models). I’m even considering adding an early CG Poser blocked‑out scene test to see how far the various editor models can take it.
With additions like structured prompts (introduced in BFL Flux 2), maybe we'll see something like this in the near future.
singhkays
2 months ago
GPT Image 1.5 is the first model that gets close to replicating the intricate detail mosaic of bullets in the "Lord of War" movie poster for me. Following the prompt instructions more closely also seems better compared to Nano Banana Pro.
I edited the original "Lord of War" poster with a reference image of Jensen and replaced bullets with GPU dies, silicon wafers and electronic components.
boredhedgehog
2 months ago
I disagree with gpt-image-1.5's grade on the worm sign. It moved some of the marks around to accommodate the enlarged black area, but retained the overall appearance of the sign.
vunderba
2 months ago
I can see how you'd come to that conclusion. Each prompt is supposed to illustrate a different type of test criteria. The ultimate goal of Worm Sign is intended to test a near 100% retention of the original weathered/dented sign.
If you look at the ones that passed (Flux.2 Pro, Gemini 2.5 Flash, Reve), you'll see that they did not add/subtract/move any of the pockmarks from the original image.
leumon
2 months ago
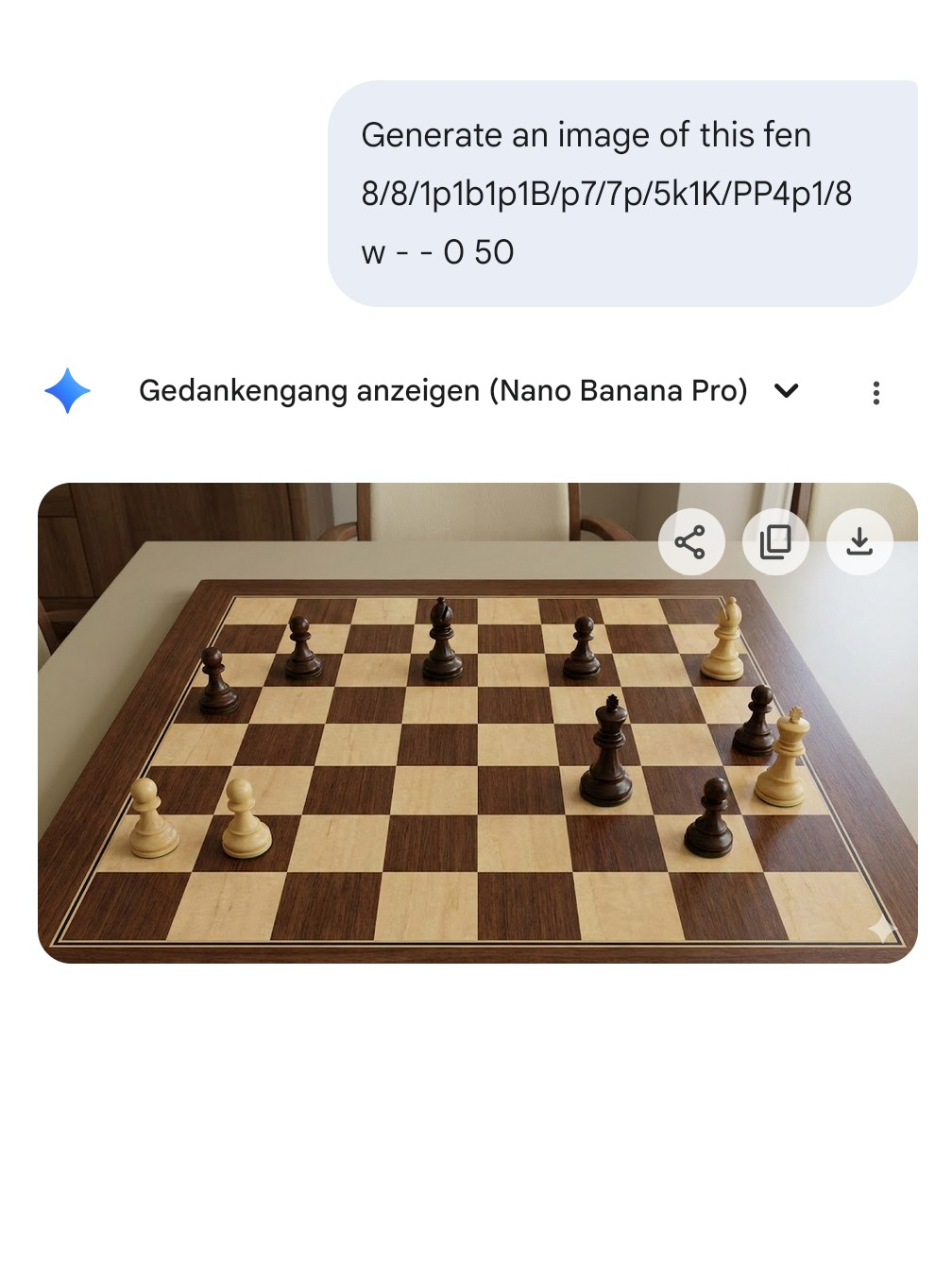
One other test you could add is generating a chessboard from a FEN. I was surprised to see NBP able to do that (however, it seems to only work with fewer pieces, after a certain amount it makes mistakes or even generates a completely wrong image) https://files.catbox.moe/uudsyt.png
{kind=link}
nicpottier
2 months ago
Love this benchmark, always the first place I look. Also seems like it is time to move the goalposts, not sure we are getting enough resolution between models anymore.
Out of curiosity why does gemini get gold for the poker example but gpt-image 1.5 does not? I couldn't see a difference between the two.
llmthrow0827
2 months ago
It failed my benchmark of a photo of a person touching their elbows together.
Bombthecat
2 months ago
I can't click the compliance info button on mobile. The text shows for half a second and then vanishes. Long press just marks the text for copy paste.
vunderba
2 months ago
Hey bombthecat - thanks for pointing this out. I had some poor mobile browser detection that was causing this issue. It should be fixed now.
BoredPositron
2 months ago
Nano Banana has still the best VAE we have seen especially if you are doing high res production work. The flux2 comes close but gpt image is still miles away.
heystefan
2 months ago
So when you say "X attempts" what does that mean? You just start a new chat with the same exact prompt and hope for a different result?
vunderba
2 months ago
All images are generated using independent, separate API calls. See the FAQ at the bottom under “Why is the number of attempts seemingly arbitrary?” and “How are the prompts written?” for more detail, but to quickly summarize:
In addition to giving models multiple attempts to generate an image, we also write several variations of each prompt. This helps prevent models from getting stuck on particular keywords or phrases, which can happen depending on their training data. For example, while “hippity hop” is a relatively common name for the ball-riding toy, it’s also known as a “space hopper.” In some cases, we may even elaborate and provide the model with a dictionary-style definition of more esoteric terms.
This is why providing an “X Attempts” metric is so important. It serves as a rough measure of how “steerable” a given model is - or put another way how much we had to fight with the model in order for it to consistently follow the prompt’s directives.
mvkel
2 months ago
This leaderboard feels incredibly accurate given my own experience.
lobochrome
2 months ago
Stupid Cisco Umbrella is blocking you
irishcoffee
2 months ago
> the only model that legitimately passed the Giraffe prompt.
10 years ago I would have considered that sentence satire. Now it allegedly means something.
Somehow it feels like we’re moving backwards.
echelon
2 months ago
> Somehow it feels like we’re moving backwards.
I don't understand why everyone isn't in awe of this. This is legitimately magical technology.
We've had 60+ years of being able to express our ideas with keyboards. Steve Jobs' "bicycle of the mind". But in all this time we've had a really tough time of visually expressing ourselves. Only highly trained people can use Blender, Photoshop, Illustrator, etc. whereas almost everyone on earth can use a keyboard.
Now we're turning the tide and letting everyone visually articulate themselves. This genuinely feels like computing all over again for the first time. I'm so unbelievably happy. And it only gets better from here.
Every human should have the ability to visually articulate themselves. And it's finally happening. This is a major win for the world.
I'm not the biggest fan of LLMs, but image and video models are a creator's dream come true.
In the near future, the exact visions in our head will be shareable. We'll be able to iterate on concepts visually, collaboratively. And that's going to be magical.
We're going to look back at pre-AI times as primitive. How did people ever express themselves?
concats
2 months ago
“I've come up with a set of rules that describe our reactions to technologies:
1. Anything that is in the world when you’re born is normal and ordinary and is just a natural part of the way the world works.
2. Anything that's invented between when you’re fifteen and thirty-five is new and exciting and revolutionary and you can probably get a career in it.
3. Anything invented after you're thirty-five is against the natural order of things.”
― Douglas Adams
vintermann
2 months ago
Is that how it works this time, though?
* I'm into genealogy. Naturally, most of my fellow genealogists are retired, often many years ago, though probably also above average in mental acuity and tech-savviness for their age. They LOVE generative AI.
* My nieces, and my cousin's kids of the same age, are deeply into visual art. Especially animation, and cutesy Pokemon-like stuff. They take it very seriously. They absolutely DON'T like AI art.
Rodeoclash
2 months ago
Where is all this wonderful visual self expression that people are now free to do? As far as I can tell it's mostly being used on LinkedIn posts.
scrollaway
2 months ago
It’s a classic issue that you give access to superpowers to the general population and most will use them in the most boring ways.
The internet is an amazing technology, yet its biggest consumption is a mix of ads, porn and brain rot.
We all have cameras in our pockets yet most people use them for selfies.
But if you look closely enough, the incredible value that comes from these examples more than makes up for all the people using them in a “boring” way.
And anyway who’s the arbiter of boring?
irishcoffee
2 months ago
You basically described magic mushrooms, where the description came from you while high on magic mushrooms.
It’s just a tool. It’s not a world-changing tech. It’s a tool.
conradfr
2 months ago
It is amazing and impressive. But also an unlimited source of trash and slop during my internet use.
SchemaLoad
2 months ago
I'm struggling to see the benefits. All I see people using this for is generating slop for work presentations, and misleading people on social media. Misleading might be understating it too. It's being used to create straight up propaganda and destruction of the sense of reality.
user
2 months ago