rpcope1
4 months ago
If you like Forth, but find it challenging to build real stuff with, Factor (https://factorcode.org/) is most or all of the good stuff about Forth designed in a way that's much easier to do things with. It was designed by Slava Pestov (who I think had a big hand in Swift), and honestly it's a lot of fun to build webapps and other programs with, and much less brutal to read than Forth can be.
a96
4 months ago
I had to have a peek if it's all just web. Apparently, no.
https://concatenative.org/wiki/view/Factor/UI
> The Factor UI is a GUI toolkit together with a set of developer tools, written entirely in Factor, implemented on top of a combination of OpenGL and native platform APIs: X11, Win32 and Cocoa.
> UI gadgets are rendered using the cross-platform OpenGL API, while native platform APIs are used to create windows and receive events. The platform bindings can be also used independently; X11 binding has also been used in a Factor window manager, Factory, which is no longer maintained. The Cocoa binding is used directly by the webkit-demo vocabulary in Factor.
Fascinating. Probably dead and no mention of Wayland, but fascinating.
mrjbq7
4 months ago
Factor is not dead, but continues to make development progress. If you're curious you can find more information on the main page:
The latest release of 0.100 was September 2024, and we are getting close to a new release which we hope to do end of the year or so.
https://github.com/factor/factor
The cross-platform UI that Factor has works on macOS, Windows, and Linux. On Linux, it unfortunately still uses a GTK2-GLext project for the OpenGL widget that we render into, but modern GTK3/4 has a Gtk.GlArea that we need to switch to using which will improve the compatibility on Wayland. However, it works fine with even the latest Ubuntu 25.10 release.
And of course, you could use other libraries easily, such as Raylib:
arethuza
4 months ago
I have very fond memories of programming in PostScript within NeWS/HyperNeWS - it did quite a few things that I've never seen in any other environment.
Edit: To be fair relying on PostScript probably did limit the appeal, but I actually really liked it.
DonHopkins
4 months ago
Thank you fellow HyperLooker! For me, PostScript WAS the appeal!
For the rest of the civilized world, Arthur van Hoff wrote "PdB", an object oriented PostScript => C compiler.
https://news.ycombinator.com/item?id=10088193
>Arthur van Hoff wrote PdB, and we used it for to develop HyperLook (nee HyperNeWS nee GoodNeWS). You could actually subclass PostScript classes in C, and vice-verse!
https://news.ycombinator.com/item?id=29964271
>That's interesting! I love Forth, but I love PostScript even more, because it's so much like Lisp. What is it about PostScript that you dislike, that doesn't bother you about Forth?
>Arthur van Hoff wrote "PdB" for people who prefer object oriented C syntax to PostScript. I wrote some PdB code for HyperLook, although I preferred writing directly in PostScript.
Leigh Klotz used PdB at Xerox PARC, and wrote this about it here:
https://regex.info/blog/2006-09-15/247#comment-18269
>OK, I think I’ve written more PostScript by hand than Jamie, so I assume he thinks I’m not reading this. Back in the old days, I designed a system that used incredible amounts of PostScript. One thing that made it easier for us was a C-like syntax to PS compiler, done by a fellow at the Turning Institute. We licensed it and used it heavily, and I extended it a bit to be able to handle uneven stack-armed IF, and added varieties of inheritance. The project was called PdB and eventually it folded, and the author left and went to First Person Software, where he wrote a very similar language syntax for something called Oak, and it compiled to bytecodes instead of PostScript. Oak got renamed Java.
Syntactic Extensions to PdB to Support TNT Classing Mechanisms:
https://www.donhopkins.com/home/archive/NeWS/PdB.txt
Most of the built-in HyperLook components were written in C with PdB.
I wrote HyperLook wrapper components around TNT 2.0 (The NeWS Toolkit) objects like pie menus, Open Look menus, sliders, scrolling lists, buttons, etc. I used them in the HyperLook edition of SimCity, which you can see in this screen snapshot:
https://www.donhopkins.com/home/catalog/hyperlook/HyperLook-...
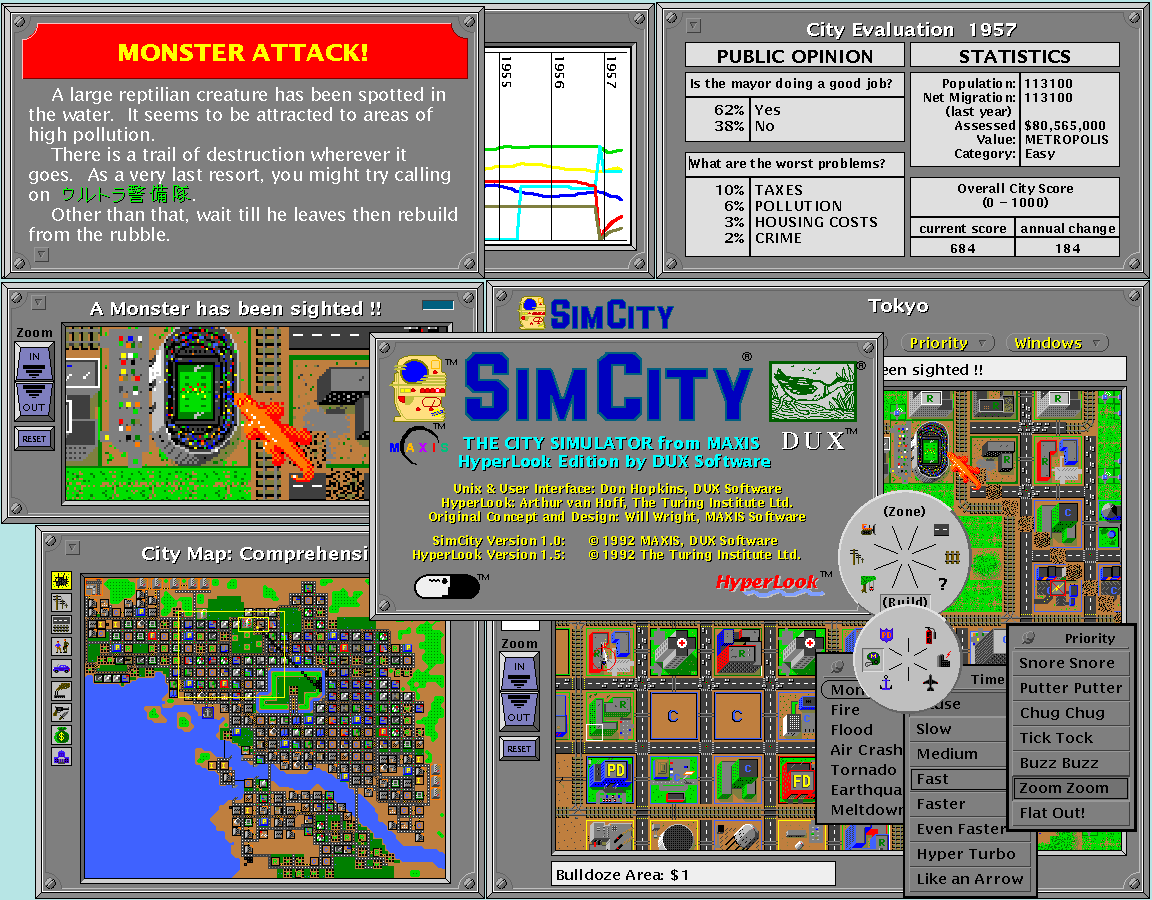{kind=link}
Arthur later went on to join Sun (James Gosling's "First Person" group), wrote the Java compiler in Java, and AWT, then left Sun to form Marimba, where they developed "Castanet" (push code and content distribution), and Bongo (HyperCard/HyperLook for Java, with a WYSIWYG UI editor and script editor, that dynamically ran the Java compiler to compile and hot patch scripts attached to objects on the fly. Which was groundbreaking at the time, though IDEs do it all the time now).
https://news.ycombinator.com/item?id=25434613
>Bongo is to Java+HyperCard as HyperLook is to PostScript+HyperCard.
Danny Goodman himself (the HyperCard book author) wrote a book about Bongo! Arthur's Forward explains it well.
https://www.amazon.com/Official-Marimba-Guide-Bongo-Goodman/...
https://archive.org/details/officialmarmba00good
>Foreward
>Marimba was formed in early 1996 by four members of the team that created Java. Kim Polese, Jonathan Payne, Sami Shaio, and I left Sun Microsystems and founded Marimba with the goal to build commercial consumer applications written entirely in Java.
>While at Sun we concentrated on creating a great multi-platform, portable, efficient, object-oriented, multi-threaded, and buzzword-compliant language. However, we paid too little attention to developing tools. In early 1996 Java was largely still a language for skilled programmers who are happy with emacs, a Java compiler, and lots of coffee. Luckily these so-called "Rambo" programmers loved Java and made it very successful.
>Creating large applications in Java turned out to be much harder than we had anticipated, so we decided that we needed better tools before we could build better applications. That is why we created Bongo. Bongo is a tool that allows you to quickly create a user interface using a variety of widgets, images, audio, and animation. After you have created a user interface you can script it in Java, or you can easily hook it up to a Java program.
>Bongo is a high-level tool that provides a clean separation of semantics and design elements.
>It allows multi-disciplinary teams to work simultaneously on a large application without getting in each other's hair. You will find that it is a very powerful tool that is great for creating good-looking, functional, but still very flexible user interfaces. In addition to the standard widgets, Bongo enables you to extend the widget set by creating new widget classes in Java.
>This means that you can develop your own set of widgets which are easily integrated into user interfaces developed with Bongo.
>One of the great features of Bongo is its capability to incorporate applets into user interfaces.
>This enables you to use applet creation tools from third-party software vendors to create components of your user interface and combine these components into a single consistent application using Bongo. This is the way of the future: In future releases, Bongo will naturally support Sun's JavaBeans which will further simplify the process of integrating components created by different tools. This way, you can choose the tools that are appropriate for the job, rather than being stuck with the tools provided by the environment.
>A lot of the ideas behind Bongo are based on a tool called Hyper NeWS which I developed for the NeWS windows system during the late '80s (NeWS was another brain-child of Sun's James Gosling). HyperNeWS used the stack, background, and card model which was popularized by Apple's HyperCard. Bongo goes a lot further than HyperNeWS by allowing arbitrary container hierarchies and scripting.
>I am really excited that Danny has written this excellent book on Bongo. It clearly explains the concepts behind Bongo, and it takes you through many examples step by step. This book is an essential tool for all serious Bongo users.
>Have fun, Arthur van Hoff, Chief Tenology Officer, Marimba, Inc.
graboid
4 months ago
Factor is super cool! And the amount of packages ("vocabularies") it comes bundled with is just astonishing.
ulbu
4 months ago
note to those interested: no apple silicon support.
mrjbq7
4 months ago
No, but works fine in Rosetta emulation. And can use native libraries installed via for example the Intel Homebrew.
We do hope to get native aarch64 support in the near future. Let's see.