bccdee
5 months ago
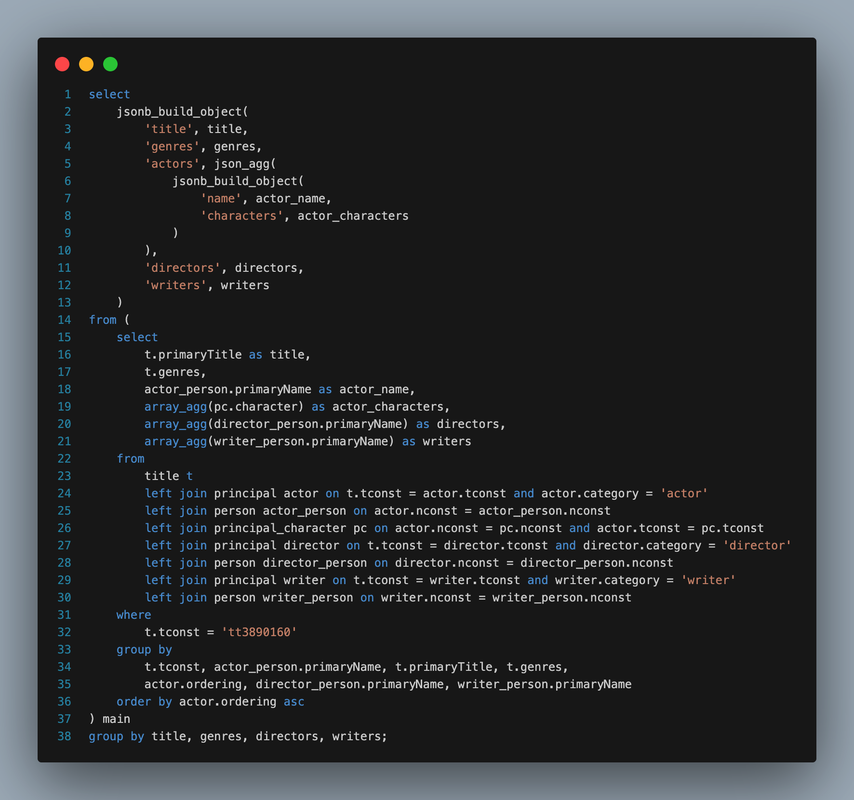
My favourite way of doing this is
with movieIds as (select id from Movie where title = $1),
actorIds as (select Actor.id from Actor join ActorMovie on [...]
where ActorMovie.Movie in movieId),
alsoActedIn as (select id from ActorMovie where actor in actorId),
movieResults as (select * from Movie where id in movieIds),
actorResults as (select * from Actor where id in actorIds),
alsoActedInResults as (select * from Movie join ActorMovie on [...]
where ActorMovie.id in alsoActedIn)
select * from movieResults
full outer join actorResults on false
full outer join alsoActedInResults on false;
MovieId,MovieTitle,ActorId,ActorName,MovieId,MovieTitle,ActorMovie.actor
0,"Indiana Jones",null,null,null,null,null
null,null,0,"Harrison Ford",null,null,null
null,null,null,null,0,"Indiana Jones",0
null,null,null,null,1,"Star Wars",0
null,null,null,null,2,"The Fugitive",0
[{
id: 0,
title: "Indiana Jones",
actors: [{
id: 0,
name: "Harrison Ford",
alsoActedIn: [
{id: 1, title: "Star Wars"},
{id: 2, title: "The Fugitive"},
]
}]
}]
This pattern has saved me from some truly awful query logic.
timeinput
5 months ago
I've been trying that, and I just keep running into miserable query performance.
What order of magnitude do you use this on and find it acceptable? 1MB, 1GB, 1TB, 1PB? At 1GB it seems okay. At 10GB things aren't great, at 100 GB things are pretty grim, and at 1TB I have to denormalize the database or it's all broken (practically).
I'm not a database expert, but I don't feel like I'm asking hard questions, but I'm running into trouble with something I thought was 'easy', and matches what you're describing.
bccdee
5 months ago
Try using the `explain analyze` statement. My guess is, either you need to add indexes, or you're not using the indexes you do have because some of your subqueries are being materialized when they shouldn't be. I can't be sure of the specific problem, but you should be able to fix it with some run-of-the-mill query optimization.
mycall
5 months ago
Chained CTEs that reference previous expressions can cause the query plan to explode sometimes. My only work around for that situation is to switch to using temp tables with indexes, replacing some (or all) of the table expressions until things are fast again.
bccdee
5 months ago
Yeah—lasy time I had that issue, I found postgres was materializing some of the subqueries and then naively scanning those materialized queries when the original tables had indexes. I fixed it by adding "not materialized" and hitting the original tables directly, but if you want to materialize a subquery AND have it be indexed, a temp table is the only way I know to make that happen.
kaelwd
5 months ago
My favourite way of doing this is with edgeql
select Movie {
title,
actors: {
name,
alsoActedIn := (
.movies { title }
filter .id != Movie.id
),
},
} filter .title = <str>$title;gerad
5 months ago
couldn't you do a union all instead of outer join on false?
bccdee
5 months ago
Nope, because unions merge columns. `select * from Actor union select * from Movies` gives you [(0, "Harrison Ford"), (0, "Indiana Jones")], which is a problem because we can't tell which rows are actors and which rows are movies. What we need is [(0, "Harrison Ford", null, null), (null, null, 0, "Indiana Jones")].
lixtra
5 months ago
Yes, you could use union. But then you have to pad the columns of the other tables with NULLs to arrive at the same output and carefully count. And we all hate counting.
taffer
5 months ago
> With a bit of client-side logic, it's easy to transform that into this [example here] without the need to use json as a middleman.
The result in your example looks exactly like JSON. Am I missing something?
Also, what is the point of avoiding JSON? Your client has to unmarshal the result either way.
bccdee
5 months ago
The json in my example would be generated in client code from the rows returned by the query, which I represented as CSV. The client's representation could just as easily be objects or protobufs or whatever, but I figured json would be a convenient way to portray nested data.
It's worth avoiding json on the wire if possible, because the extra layer of encoding will complicate things. Any good postgres integration will know how to safely deserialize and discriminate between (e.g.) DateTime and DateTimeWithTimeZone. But with json, everything's stringified.
{kind=link}